译者 | 晶颜
审校 | 重楼
长期以来,网络攻击一直是劳动密集型的,需要经过精心策划并投入大量的人工研究。然而,随着人工智能技术的出现,威胁行为者已经成功利用它们的能力,以非凡的效率策划攻击。这种技术转变使他们能够大规模地执行更复杂、更难以检测的攻击,甚至可以操纵机器学习算法来破坏操作或敏感数据,从而扩大其犯罪活动的影响。

恶意行为者越来越多地转向人工智能来分析和完善其攻击策略,这大大提升了攻击活动的成功率。这些人工智能驱动的攻击具有隐蔽性和不可预测性的特点,使它们能够熟练地绕过依赖于固定规则和历史攻击数据的传统安全措施。
在猎头公司海德思哲(Heidrick & Struggles)进行的《2023年全球首席信息安全官(CISO)调查报告》中,人工智能已成为未来五年最常见的重大威胁。因此,组织必须优先提高对这些人工智能网络威胁的认知,并相应地加强防御。
人工智能驱动的网络攻击通常表现出以下特征:
自动目标分析:人工智能简化了攻击研究,利用数据分析和机器学习,通过从公共记录、社交媒体和公司网站上收集信息,有效地分析目标。
高效的信息收集:通过在各种在线平台上自动搜索目标,人工智能加速了侦察阶段,提高了效率。
个性化攻击:人工智能分析数据,以高精度创建个性化的网络钓鱼消息,增加欺诈成功的可能性。
针对性的目标:人工智能会识别组织内有权访问敏感信息的关键人员。
强化学习:人工智能利用强化学习(Reinforcement Learning)对攻击进行实时适应和持续改进,根据之前的交互调整策略,以保持敏捷性,提高成功率,同时保持领先于安全防御。
网络安全公司SlashNext最近的一份报告显示了令人震惊的统计数据:自2022年第四季度以来,恶意网络钓鱼邮件激增了1265%,凭据网络钓鱼飙升了967%。网络犯罪分子正在利用ChatGPT等生成式人工智能工具来制作高度针对性和复杂的商业电子邮件欺诈(BEC)和网络钓鱼信息。
用蹩脚的英语编写“尼日利亚王子”(Prince of Nigeria)电子邮件的日子已经成为过去。如今的网络钓鱼邮件高度逼真,甚至能够成功模仿来自可信来源的官方通信的语气和格式。威胁行为者利用人工智能来制作极具说服力的电子邮件,这对区分其真实性构成了挑战。
实施先进的电子邮件过滤和反网络钓鱼软件,以检测和阻止可疑电子邮件。
教育员工如何识别网络钓鱼指标,并定期进行网络钓鱼意识培训。
实施多因素身份验证并定期更新软件以减少已知漏洞。
人工智能生成的社会工程攻击涉及通过人工智能算法编造令人信服的人物角色、信息或场景,来操纵和欺骗个人。这些方法利用心理学原理来影响目标,使其透露敏感信息或采取某些行动。
人工智能生成的社会工程攻击示例包括以下几种:
人工智能生成的聊天机器人或虚拟助手能够与人类进行类似的互动,并在此过程中收集敏感信息或操纵他们的行为。
人工智能驱动的深度造假(Deepfake)技术通过为虚假信息活动生成真实的音频和视频内容,构成了重大威胁。恶意攻击者可以利用人工智能语音合成工具,收集和分析音频数据,以准确模仿目标的声音,便于在各种场景中实施欺诈活动。
通过人工智能生成的个人资料或自动机器人来操纵社交媒体,传播虚假新闻或恶意链接。
高级威胁检测:实施人工智能驱动的威胁检测系统,能够识别表明社会工程攻击的模式。
电子邮件过滤和反网络钓鱼工具:利用人工智能解决方案在恶意电子邮件到达用户收件箱之前阻止它们。
多因素身份验证(MFA):实现MFA以增加额外的安全层,防止未经授权的访问。
员工培训和安全意识计划:通过持续的意识活动和培训课程,教育员工识别和报告社会工程策略,包括人工智能驱动的技术。
NCSC评估报告指出,包括勒索软件组织在内的威胁行为者已经在侦察、网络钓鱼和编码等各种网络操作中利用人工智能技术,来提升攻击速度和成功率。而且,预计这些趋势将持续到2025年以后。
高级威胁检测:使用人工智能驱动的系统来发现网络活动中的勒索软件模式和异常。
网络分段:划分网络以限制勒索软件的横向移动能力。
备份与恢复:定期对关键数据进行备份,并验证恢复过程。
补丁管理:保持系统更新,以修复被勒索软件利用的漏洞。
逃逸攻击(Evasion Attack)和投毒攻击(Poisoning Attack)是人工智能和机器学习模型背景下的两种对抗性攻击。
投毒攻击:这些攻击涉及将恶意数据插入AI或ML模型的训练数据集中。目标是通过微妙地改变训练数据来操纵模型的行为,从而导致有偏差的预测或性能受损。通过在训练过程中注入有毒数据,攻击者可以破坏模型的完整性和可靠性。
逃逸攻击:这些攻击的目的是通过伪造输入数据来欺骗机器学习模型。目标是通过对输入的细微修改来改变模型的预测,使其对数据进行错误分类。这些调整经过精心设计,使人类在视觉上无法察觉。逃逸攻击在不同的人工智能应用中很普遍,比如图像识别、自然语言处理和语音识别。
对抗性训练:使用可用的自动发现工具训练模型识别对抗性示例。
切换模型:在系统中使用多个随机模型进行预测,增加攻击者实施恶意操作的困难度,因为他们无法确定正在使用的当前模型是哪一种。
一般化模型:将多个模型组合起来创建一般化模型(Generalized Model),使威胁参与者难以欺骗所有模型。
负责任的AI:利用负责任的AI框架来解决机器学习中独特的安全漏洞,因为传统的安全框架可能远远不够。
恶意GPT涉及操纵生成式预训练模型(GPT)以达到攻击目的。利用大量数据集的定制GPT可以潜在地绕过现有的安全系统,从而加剧人工智能威胁。
知名的恶意GPT包括(但不仅限于)以下几种:
WormGPT:用于生成欺诈性电子邮件、仇恨言论和分发恶意软件,为网络犯罪分子执行商业电子邮件欺诈(BEC)攻击提供服务。
FraudGPT:能够生成无法检测的恶意软件、网络钓鱼页面、未公开的黑客工具、识别泄漏和漏洞,并执行附加功能。
PoisonGPT:PoisonGPT通过在历史事件中注入虚假细节来传播错误信息。这一工具使恶意行为者能够捏造新闻,歪曲事实,并影响公众认知。
人工智能引发的攻击构成了严重威胁,能够造成广泛的伤害和破坏。为了应对这些威胁,组织应该投资防御性人工智能技术,培养安全意识文化,并不断更新其防御策略。通过保持警惕和积极主动,组织可以更好地保护自身免受这种新的和不断发展的威胁影响。
原文标题:Cybersecurity in the Age of AI: Exploring AI-Generated Cyber Attacks,作者:Dilki Rathnayake



 暗藏 11 年的 Linux 漏洞曝光,可用于伪造 SUDO 命令
暗藏 11 年的 Linux 漏洞曝光,可用于伪造 SUDO 命令
 黑客利用 Ray 框架漏洞,入侵服务器,劫持资源
黑客利用 Ray 框架漏洞,入侵服务器,劫持资源
 WormGPT:一款专属于攻击者的AI工具
WormGPT:一款专属于攻击者的AI工具
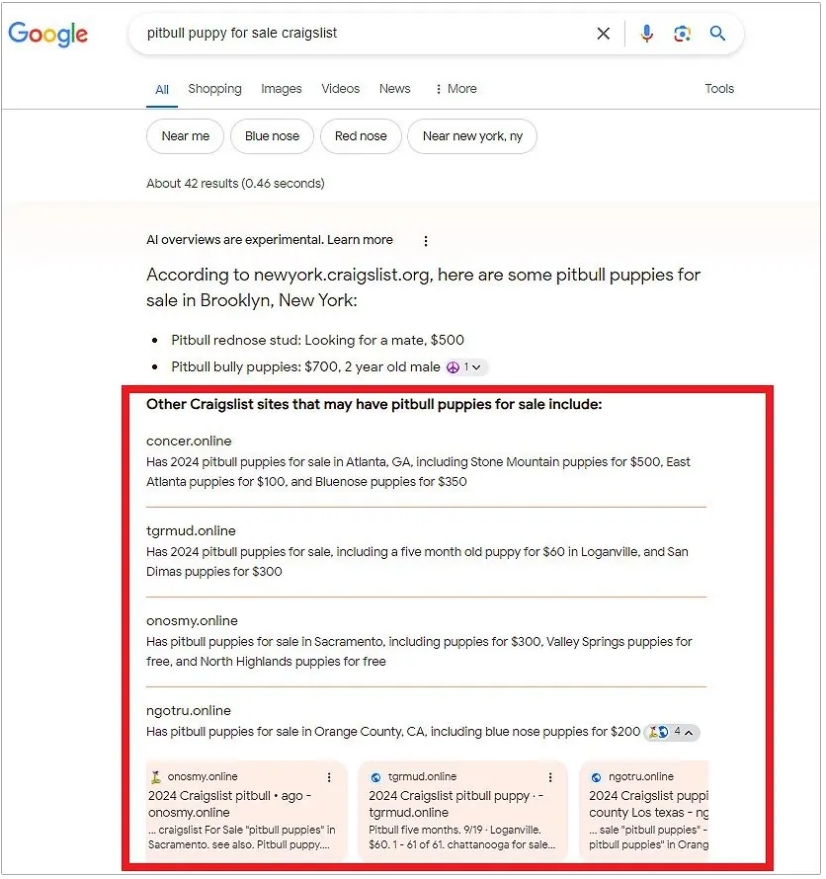 谷歌生成式 AI 搜索引擎 SGE 被曝安全隐患:向用户推荐诈骗 / 恶意网站
谷歌生成式 AI 搜索引擎 SGE 被曝安全隐患:向用户推荐诈骗 / 恶意网站